在开始正文前,我们需要明确两个概念名词 [字符集] [编码规则]
- 字符集:字符的集合,将每一个集合内字符对应到一个数字,形成一个很长的对应表,如:ASCII码表 98对应
‘b’ - 编码规则:将字符编码和解码的规则,如:计算机收到 98(二进制 01100010)查表后就会显示字母
'b',存储同理
历史说起
计算机的硬件部分(CPU,内存)是仅能识别二进制的信号,像我们平常看的小说、视频等媒体文件都是需要转换成二进制才能保存和传输的。
ASCII码
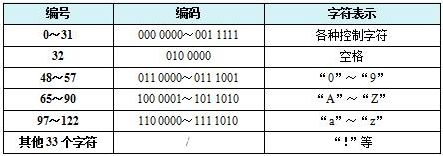
最开始的时候,美国计算机研究者为了让计算机能够识别简单的英文,对常见的字符集制定了映射规则,组成了著名的 ASCII码表 。它是由 7 位 二进制去映射 大小写字母,数字0到9、标点符号等。
我们知道 1个字节(byte)= 8 位(bit),1 bit 仅能代表 一个 0 或者 1,7位最多能代表 2*7=128(2的7次方)
欧洲拉丁文扩充
在计算机引入其他国家后,就对 原来的 128 个字符进行扩充了,加入了128个拉丁文,这样 字符表就占用了 1个字节(256个字符)
历史的局限性立马就显现了,世界国家那么多,256个字符肯定是远远不够的
自成一体
在计算机进入中国(其他国家也一样)后,成千上万的汉字需要收录进字符表,我们就使用了2个字节去存储字符,为了不与 ASCII码表 冲突,我们规定 当一个字节在128以内时,还是ASCII码表对应的字符;超出128的,需要与后面一个字节组合解读成一个字符。 这套字符集的命名以 GB(国标)开头,有过几次扩充(GB2312、GBK、GB18030),但相互间不完全兼容
大一统
随着互联网时代的到来,统一的字符集变得非常需要,Unicode 应运而生。Unicode 包含了各国的字符,而且还在不断扩充,
至 2019年5月 为止,Unicode 字符集 共收录了 137929 个字符
Unicode转换格式(Unicode Transformation Format,简称为 UTF)。
更多
更多优秀内容,可以通过 关注微信公众号【极客收藏夹】获取哦!
